CrewAI Production Readiness: Where AI Agents Still Break
Assess CrewAI production readiness for client work: hallucination loops, latency, observability, tool safety, retry control, evaluation harnesses, and human fallback.
Last Updated on July 16, 2026 by Triumphoid Team
There’s a growing expectation—bordering on hype—that “autonomous agents” can replace structured workflows. Spin up a few roles, wire tasks together, let the system think for itself, and somehow you get reliable output you can sell to a client with an SLA attached.
That’s the theory.
I tried to operationalize it. Specifically, I attempted to build an autonomous research agent for a client—something that could gather sources, synthesize insights, and deliver structured outputs without constant human intervention.
It worked.
Until it didn’t.
And the failures weren’t edge cases—they were systemic.
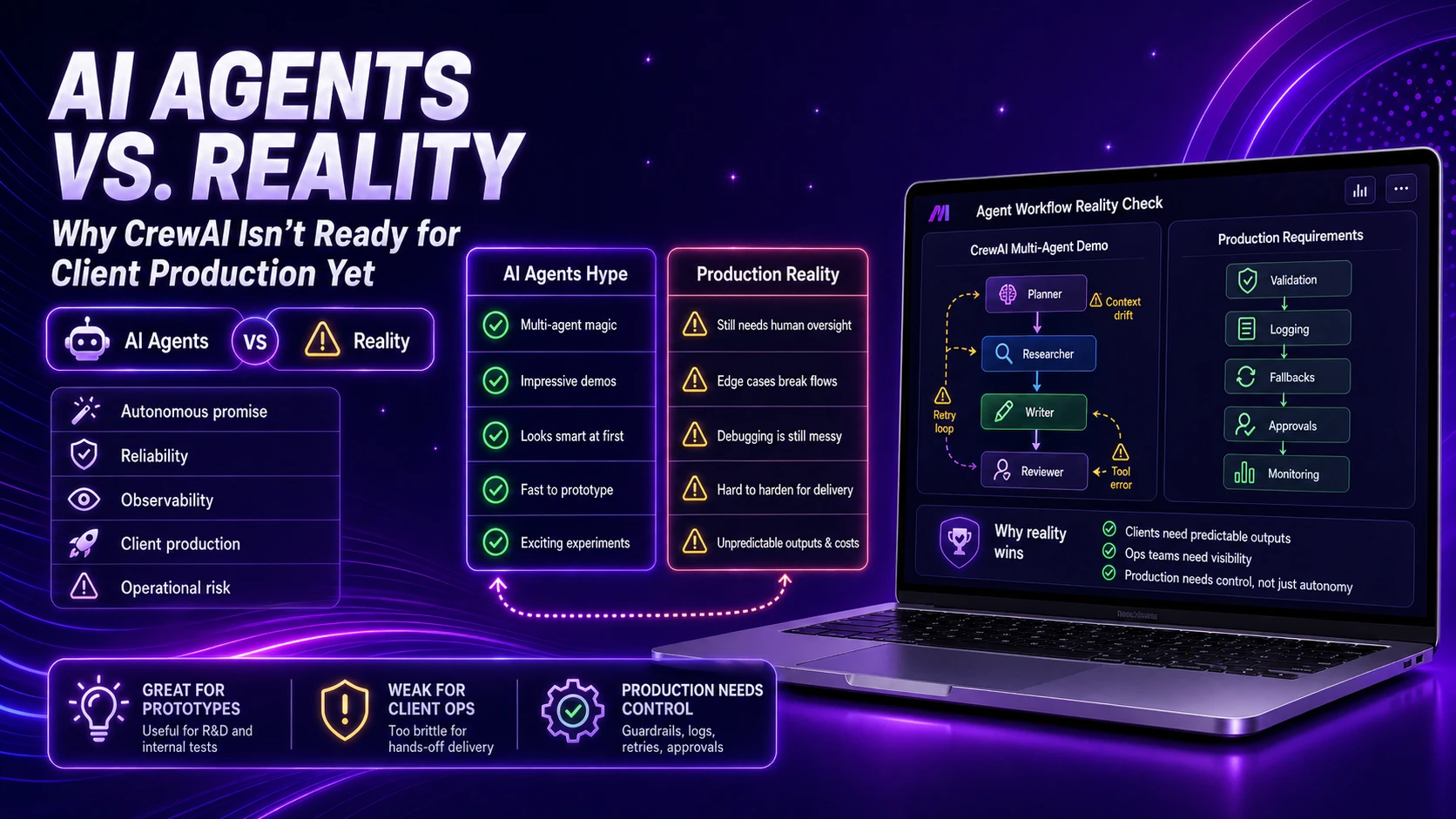
What CrewAI Actually Looks Like When You Build Something Real
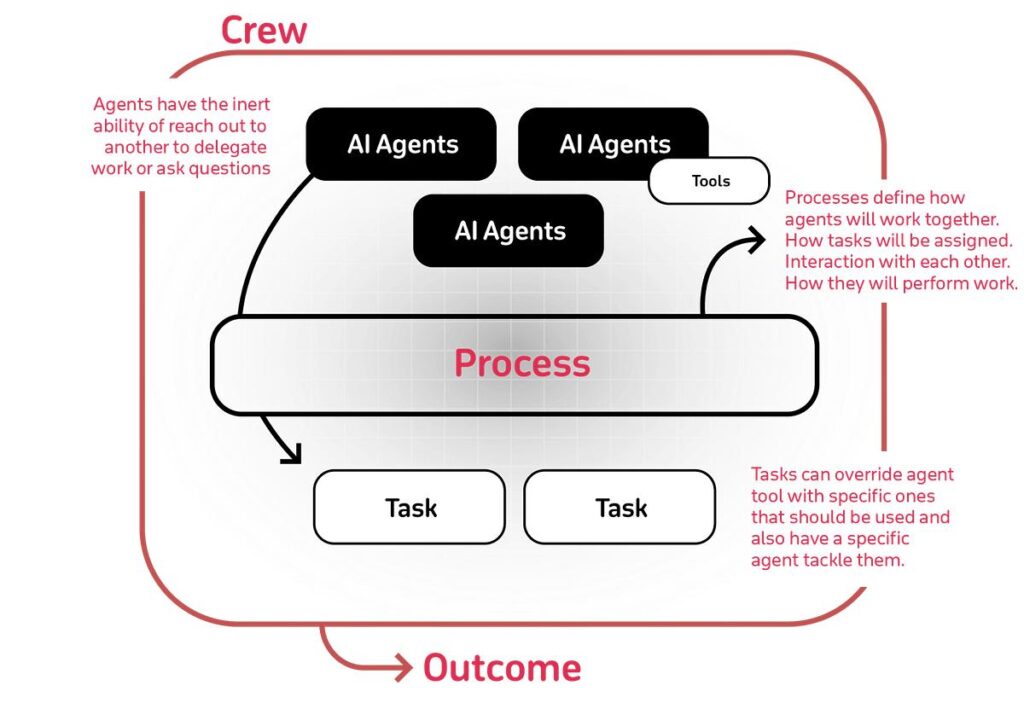
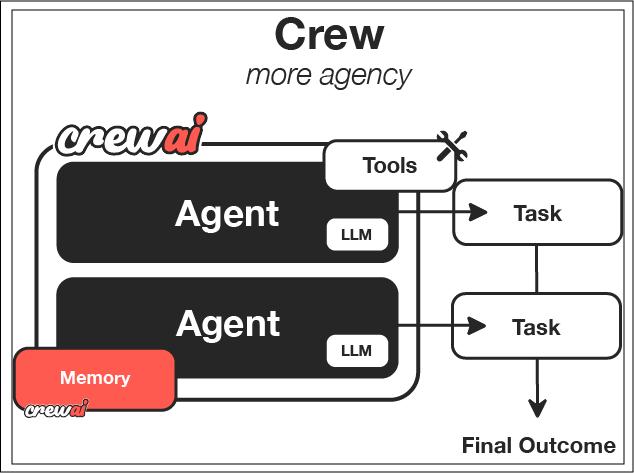
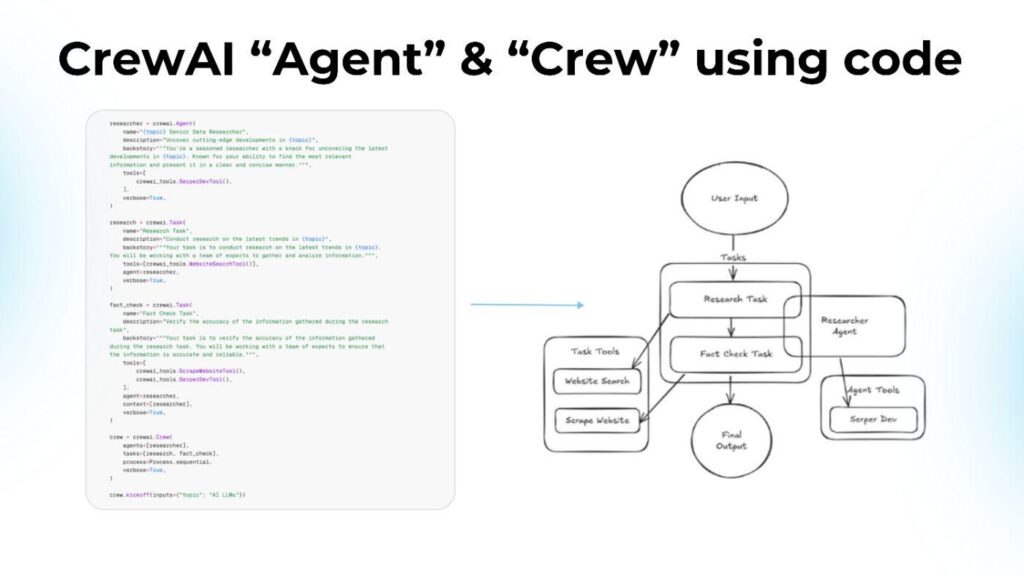
What the screenshot shows:
A typical CrewAI setup where multiple agents (researcher, analyst, writer) are defined with roles and tasks, then executed as a coordinated system. The structure looks clean—roles, goals, delegation.
That structure is exactly what makes it compelling.
And misleading.
The Use Case: Autonomous Research Agent
The goal was simple on paper:
- input: topic
- output: structured research summary
- constraints: sources, citations, formatting
The architecture looked like this:
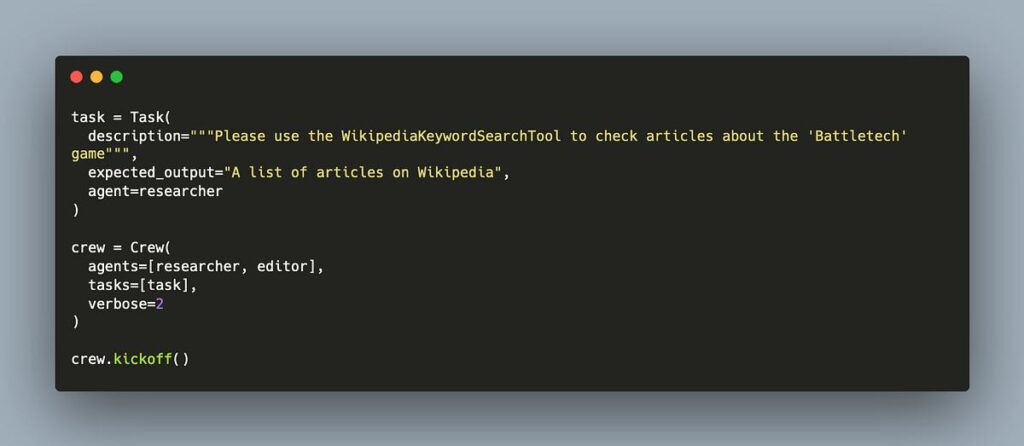
from crewai import Agent, Task, Crew
researcher = Agent(
role="Researcher",
goal="Find relevant sources",
backstory="Expert in sourcing information"
)
analyst = Agent(
role="Analyst",
goal="Summarize findings",
backstory="Expert in analysis"
)
task = Task(
description="Research and summarize AI automation tools",
agent=researcher
)
crew = Crew(
agents=[researcher, analyst],
tasks=[task]
)
crew.kickoff()
At first glance, this feels like orchestration.
In reality, it’s controlled chaos.
Where It Breaks: Hallucination Loops
The first serious issue wasn’t wrong answers.
It was recursive wrong answers.
What a Hallucination Loop Looks Like
- Agent generates incorrect assumption
- Passes it to next agent
- Next agent builds on it
- System reinforces error
- Output becomes confidently wrong
And because agents “trust” each other’s outputs, errors compound instead of getting corrected.
Example Failure Pattern
| Step | Agent Output | Problem |
|---|---|---|
| Researcher | “Tool X supports API Y” | Incorrect |
| Analyst | Builds summary around it | Reinforces error |
| Writer | Produces final output | Looks polished but wrong |
No exception thrown.
No error logged.
Just… incorrect output with confidence.
That’s worse than failure.
That’s false confidence.
Why This Happens (Technically)
CrewAI doesn’t validate truth. It chains reasoning.
Each agent operates on:
- previous outputs
- prompt instructions
- model inference
There is no built-in:
- verification layer
- fact-checking mechanism
- external grounding enforcement
So the system becomes a feedback loop of language, not reality.
Latency: The Silent SLA Killer
Let’s talk about the second issue.
Latency.
Not just “slow sometimes.”
Unpredictably slow.
Execution Timeline Reality
| Step | Expected | Actual |
|---|---|---|
| Single agent task | 2–5 sec | 5–20 sec |
| Multi-agent chain | 10–20 sec | 30–120 sec |
| Complex research task | ~30 sec | 2–5 minutes |
And here’s the real problem:
It’s not consistent.
You can’t promise:
- response time
- completion window
- throughput
Which means you can’t define an SLA.
Why Latency Becomes Unmanageable
CrewAI introduces:
- sequential agent execution
- multiple LLM calls
- retry behavior
- prompt expansion overhead
Each step adds variability.
Even if each call is “fast,” chaining them creates:
- cumulative delay
- unpredictable spikes
The SLA Problem (This Is Where It Breaks for Clients)
Let’s be honest.
Clients don’t care about agents.
They care about:
- reliability
- predictability
- consistency
And this is where CrewAI collapses.
What Clients Expect
| Requirement | Expectation |
|---|---|
| Response time | Predictable |
| Output quality | Consistent |
| Error handling | Transparent |
| Throughput | Scalable |
What CrewAI Delivers Today
| Reality | Outcome |
|---|---|
| Variable latency | No SLA possible |
| Hallucination loops | Unreliable outputs |
| No verification layer | Manual QA required |
| Non-deterministic behavior | Hard to debug |
You cannot sell this as a production service.
Not without disclaimers that make the offering meaningless.
The Debugging Problem Nobody Talks About
What the screenshot shows:
Terminal logs of agent execution—multiple steps, responses, and outputs with little structured debugging information.
Debugging CrewAI feels like:
- reading a conversation
- guessing where it went wrong
- rerunning with slight prompt changes
There’s no:
- step-level validation
- deterministic replay
- clear failure points
You’re debugging language, not logic.
Why This Is Fundamentally Different From Automation Tools
Compare this to something like n8n or Airflow.
| System Type | Behavior |
|---|---|
| Workflow automation | Deterministic |
| Data orchestration | Predictable |
| AI agents | Probabilistic |
That difference is everything.
You can’t apply:
- SLA thinking
- system guarantees
- reliability expectations
…to something that fundamentally behaves like a probability engine.
What Needs to Change Before This Becomes Sellable
This isn’t a “tool problem.”
It’s an ecosystem problem.
1. Grounding and Verification Layers
Agents must:
- validate outputs against sources
- cross-check facts
- reject uncertain results
Right now, they don’t.
2. Deterministic Execution Options
We need:
- controlled randomness
- reproducible runs
- predictable outcomes
Without this, debugging remains guesswork.
3. Latency Control Mechanisms
- parallel execution
- caching layers
- bounded execution time
Until then, SLAs are fiction.
4. Observability and Debugging Tools
Think:
- step tracing
- output validation checkpoints
- structured logs
Not conversational transcripts.
A Hard Truth About “Autonomous Agents”
The industry is selling:
“Agents that replace workflows”
But in reality, today’s agents:
- require supervision
- need validation
- behave unpredictably
They don’t replace systems.
They sit on top of them.
Where CrewAI Actually Fits Today
CrewAI is useful for:
- experimentation
- internal tools
- research assistance
- prototyping
It is not ready for:
- client-facing services
- SLA-bound systems
- mission-critical workflows
Final Thought (No Sugarcoating)
If you’re pitching “autonomous agents” to clients today, you’re not selling a solution.
You’re selling:
- unpredictability
- hidden manual work
- and a support burden you haven’t accounted for
It looks impressive in demos.
It feels innovative.
But the moment someone asks:
“Can you guarantee this will work every time?”
That’s where the conversation gets… uncomfortable.
And honestly, until that answer is “yes,”
this isn’t a product.
It’s a prototype pretending to be one.
Practitioner take: CrewAI can be useful for prototypes and internal experiments, but client production work needs a narrower question: can the agent fail predictably, surface evidence, and hand control back to a human before it burns budget or trust?
CrewAI production-readiness gate
| Production gate | Minimum standard | Why it matters |
|---|---|---|
| Task boundary | The agent has a small, testable job with clear stop conditions | Open-ended goals create loops and ambiguous success |
| Tool permissions | Read/write tools are separated and approved explicitly | Tool misuse is the fastest path from demo risk to client incident |
| Observability | Every run records prompts, tool calls, costs, latency, and outputs | You cannot improve or defend behaviour you cannot reconstruct |
| Evaluation | Regression tasks run before every prompt, model, or tool change | Agent quality drifts when evaluation is manual and anecdotal |
Use agents where recovery is cheap
The safest early production fit is an agent that drafts, triages, enriches, or recommends, while a deterministic workflow owns irreversible actions. That gives you room to improve reliability without pretending agent autonomy is mature enough for every client workflow. For monitoring design, the business observability with AIOps guide is the closest internal companion.
FAQ
Is CrewAI ready for client production?
It can be, but only for tightly bounded workflows with evaluation, observability, human fallback, and restricted tools. If the agent is expected to improvise across broad business processes, it is still too risky for most client-facing production work.
The CLEAR framework paper on enterprise agentic AI evaluation is useful because it treats reliability, latency, assurance, and cost as production concerns, not just accuracy.

