
Last Updated on February 8, 2026 by Triumphoid Team
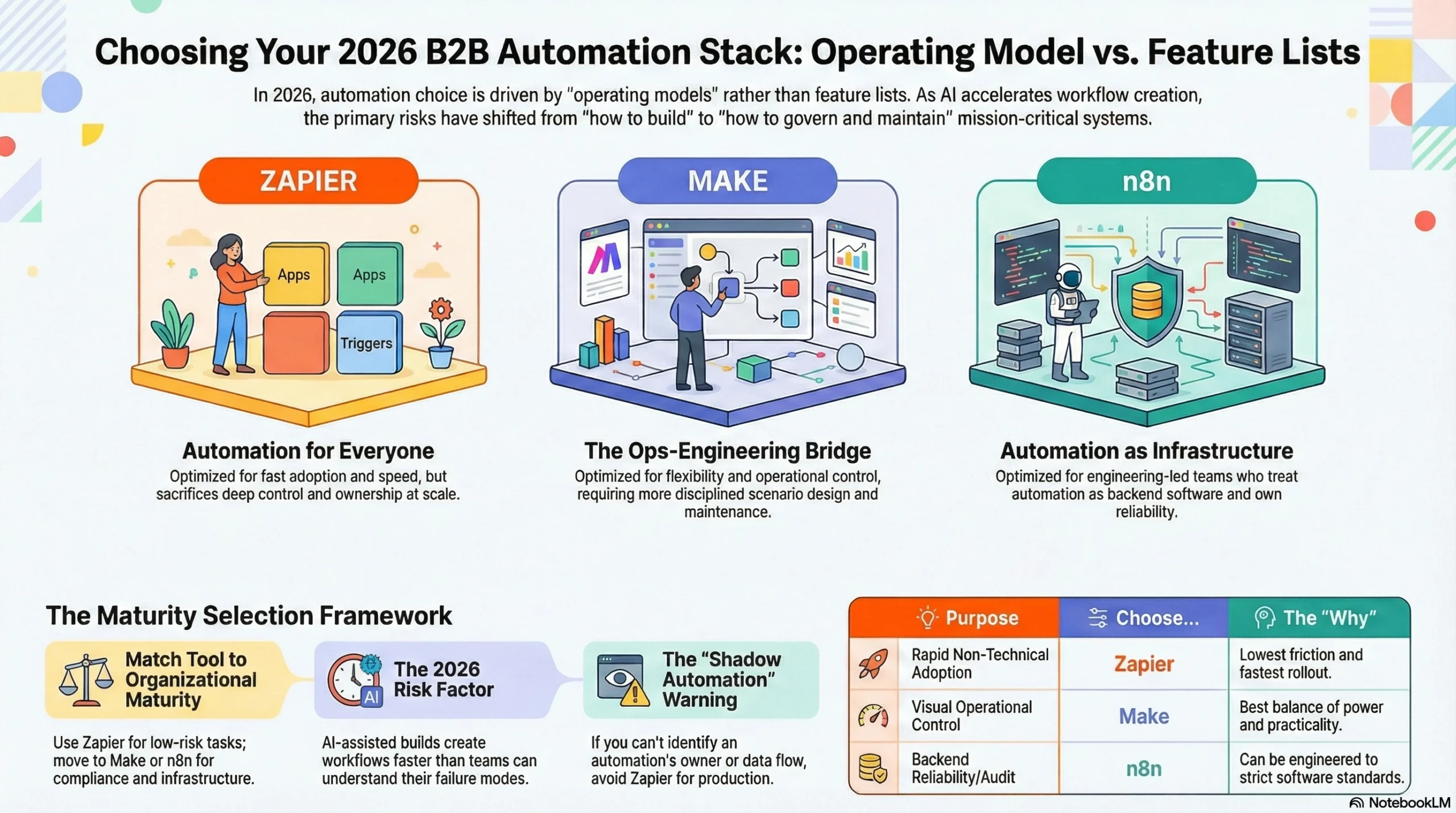
If you’re choosing between Zapier, Make, and n8n in 2026, the right decision has almost nothing to do with “feature lists” and almost everything to do with operating model.
If you want automation to spread fast across non-technical teams, Zapier wins on adoption and time-to-first-value. The tradeoff is governance debt: the more it succeeds, the more you’ll spend time untangling who owns what, why it failed, and where the credentials live.
If you want power with a visual builder and you’re willing to manage some complexity, Make is the best “ops-engineering bridge.” It’s more controllable than Zapier in practice, but you pay for that control in scenario design discipline and ongoing maintenance.
If you want a platform you can treat like part of your backend and you’re comfortable owning reliability, n8n is the only one of the three that naturally fits an engineering-led automation stack. It’s also the only one where the best outcomes are mostly determined by your team’s competence, not the vendor’s guardrails.
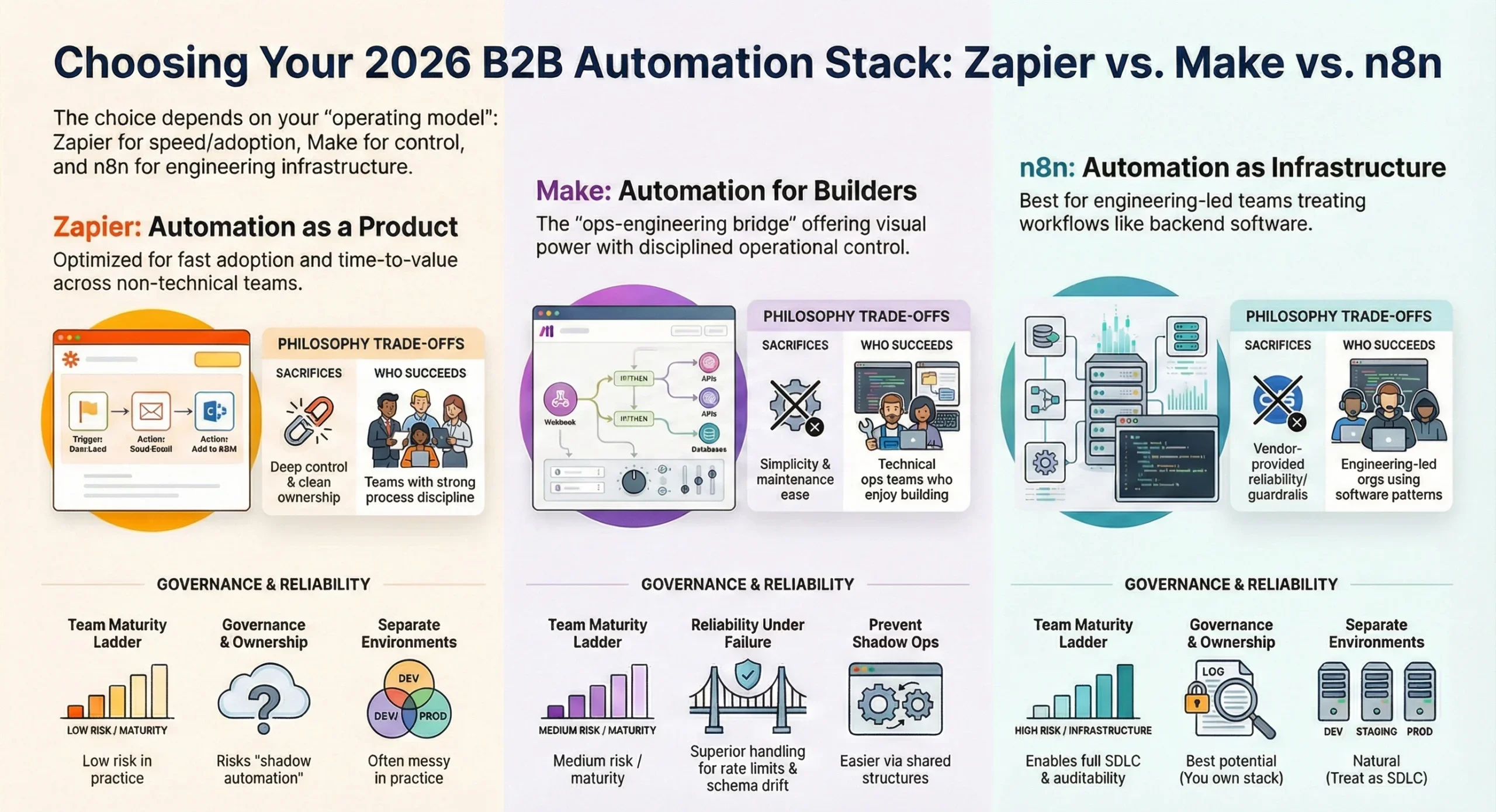
My rule: Zapier for adoption, Make for operational builds, n8n for platform thinking.
If you’re a regulated org or you’ve been burned by “shadow automation,” you should default to Make or n8n, not Zapier.
Why most comparisons are wrong?
The popular market opinion is: “Pick the tool with the most connectors and the nicest UI.”
That’s how you end up with 400 automations, no owners, a single shared admin account, and a monthly ritual where someone asks “why did finance stop syncing?” and everyone goes quiet.
Connector count is easy to market. It’s not what determines whether your automation program survives. Survivability comes from boring stuff: retry behavior, idempotency, credential isolation, change control, logging, observability, and the social system around ownership. That’s why this report compares the tools by philosophy and operational consequences.
2026 trend that changes the decision
In 2026, automation volume is being pushed up by two forces:
- AI-assisted build (people can generate workflows faster than they can understand failure modes).
- Ops cost pressure (teams are replacing headcount work with automation aggressively, then discovering that “cheap automation” becomes expensive when it breaks silently).
That combination makes governance and reliability non-negotiable. It also makes “low-code chaos” a real business risk, not just an IT pet peeve.
Comparison by philosophy
This table is the real starting point.
| Platform | Core philosophy | What it optimizes | What it sacrifices | Who succeeds with it |
|---|---|---|---|---|
| Zapier | “Automation as a product for everyone” | Adoption, simplicity, speed | Deep control, clean ownership at scale | Teams with strong process discipline (or small scope) |
| Make | “Visual automation for builders” | Flexibility, scenario design, operational control | Complexity, maintenance load | Ops + technical teams who enjoy building and maintaining systems |
| n8n | “Automation as infrastructure” | Control plane ownership, extensibility, engineering patterns | You own reliability and security | Engineering-led orgs who can treat automation as software |
My opinion: if you’re asking “which one is enterprise,” you’re already missing the point. The enterprise move is picking the tool whose philosophy matches your operating reality.
Governance fit
Governance isn’t a checkbox. It’s whether you can answer, quickly, without pain:
Who owns this automation, what data does it touch, how do we change it safely, and how do we prove what happened?
| Governance question | Zapier | Make | n8n |
|---|---|---|---|
| Can you prevent “personal account production”? | Hard unless you enforce it culturally | Easier to standardize via shared org structure | Easy if self-hosted and gated behind your auth |
| Can you separate environments cleanly (dev/stage/prod)? | Possible, often messy in practice | Practical with disciplined scenario structure | Natural (treat as SDLC) |
| Can you enforce consistent credential handling? | You can try; people will still shortcut | Better leverage; still human-dependent | Strongest if you build it properly |
| Can you audit changes and incidents like software? | Limited for serious incident response | Better operational visibility | Best potential, because you own the stack |
If your organization has ever said “we don’t know who built that,” treat that as a flashing red warning and bias toward Make or n8n.
Reliability under failure
Every automation tool looks amazing until it hits one of these: rate limits, partial outages, schema drift, webhooks failing, duplicate events, third-party connector changes.
Here’s what actually breaks.
| Failure mode | What it looks like | Zapier typical outcome | Make typical outcome | n8n typical outcome |
|---|---|---|---|---|
| Rate limits | “It worked yesterday, now it’s throttled” | Queues/backoffs can mask the problem | You can design throttling and fallbacks | You can engineer a proper queueing strategy |
| Partial outages | API returns intermittent 500s | Retries may amplify if not controlled | Scenario-level control helps | You can implement circuit breakers |
| Schema drift | Field renamed, payload changes | Silent failures are surprisingly common | Visible but maintenance-heavy | You can validate contracts explicitly |
| Duplicate events | Webhook fired twice | Duplicates creep into systems | You can implement dedupe logic | You can implement idempotency properly |
| Credential rot | Token expires, permissions change | Breaks at the worst time | Easier to centralize ownership | You control secret lifecycle |
My take: Make and n8n win here because they’re honest about reality. Zapier tries to protect you from reality; at scale that becomes frustrating, because the “simple” layer hides the exact clues you need.
Cost signals
I’m not using exact vendor pricing here because it changes constantly and becomes outdated fast. Instead, I’m showing cost behavior. That’s what matters.
Cost behavior model
| Cost driver | Zapier | Make | n8n |
|---|---|---|---|
| Volume (tasks/operations) | Can spike fast as adoption grows | Usually more predictable if scenarios are optimized | Infra costs scale; human time is the real cost |
| Retries & errors | Can quietly increase “task burn” | Can increase operations if you design poorly | Can increase infra/logging; you control it |
| Environment duplication | Often doubles/triples plan needs | Common, but manageable | Normal SDLC practice |
| Team size & access | Often increases plan tier needs | Less painful if standardized early | Not about seats; about ops maturity |
Scenario comparison: 3 common B2B realities (illustrative)
| Scenario | Description | Zapier risk | Make risk | n8n risk |
|---|---|---|---|---|
| RevOps growth | CRM → billing → data warehouse → Slack | Shadow automations + brittle ownership | Scenario sprawl if undisciplined | Engineering backlog if everything must be coded “properly” |
| Support ops | Ticket enrichment, routing, SLA, alerts | Hard to debug weird edge cases | Great, but needs maintenance | Great if you have proper logging + queues |
| Product ops | Webhooks, event processing, enrichment | Becomes “not a Zapier problem” fast | Works well if designed | Works best if treated like backend |
If you’re trying to run a mission-critical pipeline through Zapier because it was fast to build, you’ll eventually pay for that speed in incident time and credibility loss.
Tool selection framework
Most teams choose tools backwards: they start with a tool, then try to force their org into it. Flip it.
Team maturity ladder
| Maturity | Your reality | Best default |
|---|---|---|
| Level 1 | A few automations, low risk | Zapier |
| Level 2 | Cross-team workflows, moderate risk | Make |
| Level 3 | Compliance, audit needs, high volume | Make or n8n |
| Level 4 | Automation is infrastructure | n8n |
If you’re Level 3 or 4 and you pick Zapier because “people already use it,” you’ll spend the next year trying to turn a convenience tool into a governance platform.
My Experience with “automation that scaled too fast”
I’ve seen the same pattern play out across different companies and stacks.
Phase 1 is exciting: someone automates lead routing, then onboarding, then enrichment, then alerts. Everyone feels clever. Then the system becomes popular, and popularity creates entropy.
Phase 2 is the first incident where money or customer trust is on the line. A token expires, a connector changes behavior, or a webhook duplicates events. The business doesn’t say “automation failed.” They say “ops failed.” And now automation has to behave like software, but it wasn’t built like software.
Phase 3 is the awkward conversation: who owns automations? Who approves changes? Where are the logs? Why do we have five versions of the same workflow? This is where teams either mature into Make/n8n-style discipline, or they quietly roll back to manual work because “automation is unreliable.”
The painful lesson: you don’t get to choose whether automation is production software. Reality chooses it for you. The only choice is whether you act like it.
What did not work

These are the approaches that look reasonable and still fail.
| What people try | Why it fails | What to do instead |
|---|---|---|
| “Let everyone automate freely” | Shadow automation + no ownership | Centralize credentials + publish standards |
| “One admin account for everything” | Security nightmare, no accountability | Role-based access + environment separation |
| “We’ll document later” | Later never comes | Require an owner + description per workflow |
| “Retries fix reliability” | Retries can amplify outages | Add backoff + idempotency + circuit breakers |
| “We can govern with a spreadsheet” | Not enforceable | Use naming standards + org structure + review gates |
If you recognize your org in any of those, you’re not alone. It’s extremely common. It’s also fixable, but only if you stop treating automation like a side hobby.
Pro-Tip (technical callout)
Pro-Tip: Build idempotency into the workflow boundary, not inside random steps.
If your workflow is triggered by webhooks, design around a stable event key (or computed hash of the payload + timestamp bucket) and persist it. Your goal is: “same event, same result, no duplicates.” Without idempotency, retries + duplicates will eventually corrupt data, and you’ll spend hours doing forensic cleanup.
Recommendation matrix
If you only want one table to make the decision, it’s this.
| If your priority is… | Pick | Why |
|---|---|---|
| Fast adoption across non-technical teams | Zapier | Lowest friction, fastest rollout |
| Operational control with a visual builder | Make | Best balance of power and practicality |
| Treat automation like part of your backend | n8n | You can engineer it to your standards |
| Governance + audit pressure | Make or n8n | You need controllability, not “magic” |
| Minimal maintenance overhead | Zapier (small scope) | But only if you keep scope small |
My blunt take: Zapier is a great entry drug. Make is a great operating tool. n8n is a platform decision. Choose accordingly.
FAQ
Which is best: Zapier, Make, or n8n?
Best depends on operating model: Zapier for adoption, Make for controlled ops builds, n8n for engineering-led automation.
Is n8n cheaper than Zapier?
It can be, but only if you already have the engineering and ops discipline. Otherwise you “pay” in human time and reliability work.
Can Make replace Zapier?
For many B2B teams, yes—especially when governance and reliability start to matter more than speed.
When should a company move off Zapier?
When automations touch revenue, compliance, or customer experience and you can’t answer ownership/audit questions quickly.
Rhetorical gut-check: are you choosing a tool for how fast it builds workflows… or for how it behaves when a mission-critical workflow fails at 2:07 AM?


